搜索框与搜索结果的代码模板:以蘑菇博客为例
搜索框-前端
我从原来的代码文件里将相关代码复制粘贴到新文件test1.vue中,并将路径添加到全局路由,可用
显示代码
./mogu_blog_v2/vue_mogu_web/src/views/home.vue line 106-121
<div class="searchbox">
<div id="search_bar" :class="(showSearch || keyword.length > 0)?'search_bar search_open':'search_bar'">
<input
ref="searchInput"
class="input"
placeholder="想搜点什么呢.."
type="text"
name="keyboard"
v-model="keyword"
v-on:keyup.enter="search"
>
<p class="search_ico" @click="clickSearchIco" :style="(browserFlag == 1)?'':'top:17px'">
<span></span>
</p>
</div>
</div>显示效果:
事件处理
按下搜索图标时:
./mogu_blog_v2/vue_mogu_web/src/views/home.vue line 1205-1212
clickSearchIco: function () {
if (this.keyword != "") {
this.search();
}
this.showSearch = !this.showSearch;
//获取焦点
this.$refs.searchInput.focus();
}键盘按下Enter时及按下搜索时调用:
./mogu_blog_v2/vue_mogu_web/src/views/home.vue line 728-739
search: function () {
if (this.keyword == "" || this.keyword.trim() == "") {
this.$notify.error({
title: '错误',
message: "关键字不能为空",
type: 'success',
offset: 100
});
return;
}
this.$router.push({path: "/list", query: {keyword: this.keyword, model: this.searchModel}});
},一些无关紧要的逻辑
browserFlag, getBrowser, setSize(), mounted()等及其依赖的后端请求API
用于根据浏览器状态决定搜索框是否展开,与基本功能关系不太
挖掘方法
手工挖掘流程
- 阅读home.vue文件中的代码
- 找到搜索框对应的
<template>代码,加入test1.vue文件 - 找出
<template>代码中涉及到的js变量,如showSearch、keyword - 到
<script>部分寻找这些变量的定义和为这些变量赋值的方法,加入test1.vue文件 - 递归寻找新增的方法中涉及到的新变量,回到4
效果
- 能跑
- 有冗余 -> 是否继续递归下去需要考虑
- 仅考虑template(html)和js,未考虑css的问题
搜索结果
点击搜索后,重定向到新页面路径this.$router.push({path: "/list", query: {keyword: this.keyword, model: this.searchModel}});
- 原url:
${baseurl}/#/test1等有搜索框的等可以 - 新url:
${baseurl}/#/list?keyword=2&model=0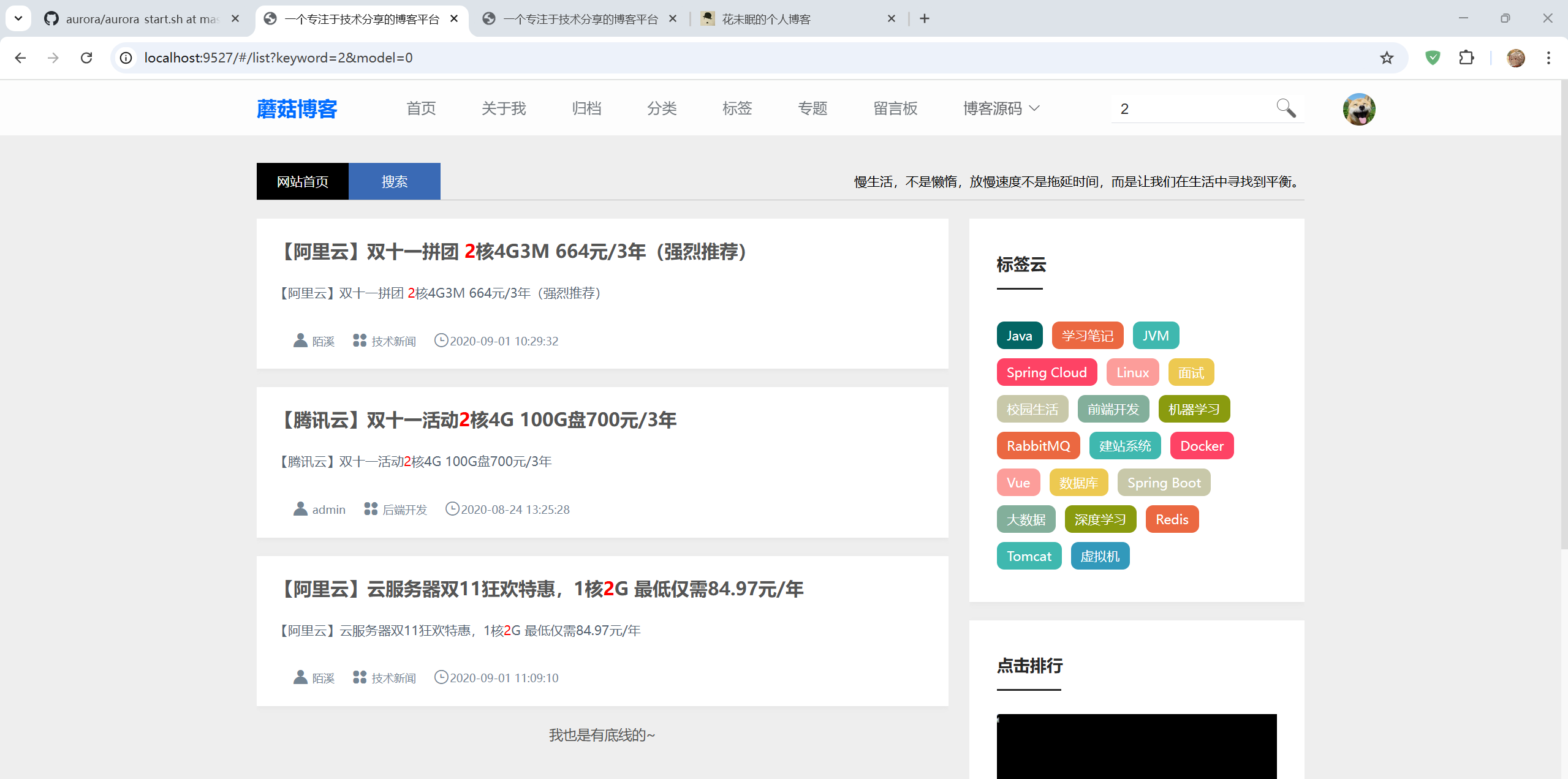
显示代码
./mogu_blog_v2/vue_mogu_web/src/views/list.vue line 11-68
<!--blogsbox begin-->
<div class="blogsbox">
<div
v-for="item in blogData"
:key="item.uid"
class="blogs"
data-scroll-reveal="enter bottom over 1s"
>
<h3 class="blogtitle">
<a
href="javascript:void(0);"
@click="goToInfo(item)"
v-html="item.title"
>{{ item.title }}</a>
</h3>
<span class="blogpic">
<a href="javascript:void(0);" @click="goToInfo(item)" title>
<img v-if="item.photoUrl" :src="item.photoUrl" alt="">
</a>
</span>
<p class="blogtext" v-html="item.summary">{{ item.summary }}</p>
<div class="bloginfo">
<ul>
<li class="author">
<span class="iconfont"></span>
<a href="javascript:void(0);" @click="goToAuthor(item.author)">{{ item.author }}</a>
</li>
<li class="lmname" v-if="item.blogSortName">
<span class="iconfont"></span>
<a href="javascript:void(0);" @click="goToList(item.blogSortUid)">{{ item.blogSortName }}</a>
</li>
<li class="createTime"><span class="iconfont"></span>{{ item.createTime }}</li>
</ul>
</div>
</div>
<div class="isEnd">
<div
class="loadContent"
@click="loadContent"
v-if="!isEnd && !loading && totalPages>0"
>点击加载更多
</div>
<div class="lds-css ng-scope" v-if="!isEnd && loading">
<div style="width:100%;height:100%" class="lds-facebook">
<div></div>
<div></div>
<div></div>
</div>
</div>
<span v-if="blogData.length >= 0 && isEnd &&!loading && totalPages>0">我也是有底线的~</span>
<span v-if="totalPages == 0 && !loading">空空如也~</span>
</div>
</div>
<!--blogsbox end-->事件处理
- 进入页面时即根据参数进行查询,入口在created()中
- created()调用search()
- search()调用convertSearchData()及一系列依赖的后端请求API
- …
经过注释检查,整个list.vue文件里面的js代码全都会被调用到
API调用
import {getBlogByUid} from "../api/blogContent";
import {searchBlog, searchBlogByAuthor, searchBlogByES, searchBlogBySort, searchBlogByTag} from "../api/search";API定义示例,后面的后端请求也以此为例:
/**
* 通过SQL搜索博客
* @param params
*/
export function searchBlog (params) {
return request({
url: process.env.WEB_API + '/search/sqlSearchBlog',
method: 'get',
params
})
}后端请求的处理
Controller
通过VSCode全局搜索/search/sqlSearchBlog找到对应的Controller在mogu_web模块的com.moxi.mogublog.web.restapi.SearchRestApi下 line 33-52
@RestController
@RequestMapping("/search")
@Api(value = "SQL搜索相关接口", tags = {"SQL搜索相关接口"})
@Slf4j
public class SearchRestApi {
@Autowired
private BlogService blogService;
@Autowired
private SystemConfigService systemConfigService;
/**
* 使用SQL语句搜索博客,如需使用Solr或者ElasticSearch 需要启动 mogu-search
*
* @param keywords
* @param currentPage
* @param pageSize
* @return
*/
@BussinessLog(value = "搜索Blog", behavior = EBehavior.BLOG_SEARCH)
@ApiOperation(value = "搜索Blog", notes = "搜索Blog")
@GetMapping("/sqlSearchBlog")
public String sqlSearchBlog(@ApiParam(name = "keywords", value = "关键字", required = true) @RequestParam(required = true) String keywords,
@ApiParam(name = "currentPage", value = "当前页数", required = false) @RequestParam(name = "currentPage", required = false, defaultValue = "1") Long currentPage,
@ApiParam(name = "pageSize", value = "每页显示数目", required = false) @RequestParam(name = "pageSize", required = false, defaultValue = "10") Long pageSize) {
if (StringUtils.isEmpty(keywords) || StringUtils.isEmpty(keywords.trim())) {
return ResultUtil.result(SysConf.ERROR, MessageConf.KEYWORD_IS_NOT_EMPTY);
}
return ResultUtil.result(SysConf.SUCCESS, blogService.getBlogByKeyword(keywords, currentPage, pageSize));
}
}Service
阅读Controller的代码,发现调用blogService.getBlogByKeyword方法
Service类存放在另一个包下,import com.moxi.mogublog.xo.service.BlogService;
且BlogService是一个接口类 line 272-280
public interface BlogService extends SuperService<Blog> {
/**
* 通过关键字搜索博客列表
*
* @param keywords
* @param currentPage
* @param pageSize
* @return
*/
public Map<String, Object> getBlogByKeyword(String keywords, Long currentPage, Long pageSize);
}存在一个父类(接口)SuperService
点击IDEA的智能跳转,找到该接口的实现BlogServiceImpl line 1437-1523
@Override
public Map<String, Object> getBlogByKeyword(String keywords, Long currentPage, Long pageSize) {
final String keyword = keywords.trim();
QueryWrapper<Blog> queryWrapper = new QueryWrapper<>();
queryWrapper.and(wrapper -> wrapper.like(SQLConf.TITLE, keyword).or().like(SQLConf.SUMMARY, keyword));
queryWrapper.eq(SQLConf.STATUS, EStatus.ENABLE);
queryWrapper.eq(SQLConf.IS_PUBLISH, EPublish.PUBLISH);
queryWrapper.select(Blog.class, i -> !i.getProperty().equals(SQLConf.CONTENT));
queryWrapper.orderByDesc(SQLConf.CLICK_COUNT);
Page<Blog> page = new Page<>();
page.setCurrent(currentPage);
page.setSize(pageSize);
IPage<Blog> iPage = blogService.page(page, queryWrapper);
List<Blog> blogList = iPage.getRecords();
List<String> blogSortUidList = new ArrayList<>();
Map<String, String> pictureMap = new HashMap<>();
final StringBuffer fileUids = new StringBuffer();
blogList.forEach(item -> {
// 获取图片uid
blogSortUidList.add(item.getBlogSortUid());
if (StringUtils.isNotEmpty(item.getFileUid())) {
fileUids.append(item.getFileUid() + SysConf.FILE_SEGMENTATION);
}
// 给标题和简介设置高亮
item.setTitle(getHitCode(item.getTitle(), keyword));
item.setSummary(getHitCode(item.getSummary(), keyword));
});
// 调用图片接口,获取图片
String pictureList = null;
if (fileUids != null) {
pictureList = this.pictureFeignClient.getPicture(fileUids.toString(), SysConf.FILE_SEGMENTATION);
}
List<Map<String, Object>> picList = webUtil.getPictureMap(pictureList);
picList.forEach(item -> {
pictureMap.put(item.get(SQLConf.UID).toString(), item.get(SQLConf.URL).toString());
});
Collection<BlogSort> blogSortList = new ArrayList<>();
if (blogSortUidList.size() > 0) {
blogSortList = blogSortService.listByIds(blogSortUidList);
}
Map<String, String> blogSortMap = new HashMap<>();
blogSortList.forEach(item -> {
blogSortMap.put(item.getUid(), item.getSortName());
});
// 设置分类名 和 图片
blogList.forEach(item -> {
if (blogSortMap.get(item.getBlogSortUid()) != null) {
item.setBlogSortName(blogSortMap.get(item.getBlogSortUid()));
}
//获取图片
if (StringUtils.isNotEmpty(item.getFileUid())) {
List<String> pictureUidsTemp = StringUtils.changeStringToString(item.getFileUid(), SysConf.FILE_SEGMENTATION);
List<String> pictureListTemp = new ArrayList<>();
pictureUidsTemp.forEach(picture -> {
pictureListTemp.add(pictureMap.get(picture));
});
// 只设置一张标题图
if (pictureListTemp.size() > 0) {
item.setPhotoUrl(pictureListTemp.get(0));
} else {
item.setPhotoUrl("");
}
}
});
Map<String, Object> map = new HashMap<>();
// 返回总记录数
map.put(SysConf.TOTAL, iPage.getTotal());
// 返回总页数
map.put(SysConf.TOTAL_PAGE, iPage.getPages());
// 返回当前页大小
map.put(SysConf.PAGE_SIZE, pageSize);
// 返回当前页
map.put(SysConf.CURRENT_PAGE, iPage.getCurrent());
// 返回数据
map.put(SysConf.BLOG_LIST, blogList);
return map;
}Entity 数据实体
继承自SuperEntity
对应数据库表t_blog,数据库脚本mogu_blog.sql line 94 - 471,下面只有表定义部分
/*Table structure for table `t_blog` */
DROP TABLE IF EXISTS `t_blog`;
CREATE TABLE `t_blog`
(
`uid` varchar(32) NOT NULL COMMENT '唯一uid',
`title` varchar(200) DEFAULT NULL COMMENT '博客标题',
`summary` varchar(200) DEFAULT NULL COMMENT '博客简介',
`content` longtext COMMENT '博客内容',
`tag_uid` varchar(255) DEFAULT NULL COMMENT '标签uid',
`click_count` int(11) DEFAULT '0' COMMENT '博客点击数',
`collect_count` int(11) DEFAULT '0' COMMENT '博客收藏数',
`file_uid` varchar(255) DEFAULT NULL COMMENT '标题图片uid',
`status` tinyint(1) unsigned NOT NULL DEFAULT '1' COMMENT '状态',
`create_time` timestamp NOT NULL DEFAULT '0000-00-00 00:00:00' COMMENT '创建时间',
`update_time` timestamp NOT NULL DEFAULT '0000-00-00 00:00:00' COMMENT '更新时间',
`admin_uid` varchar(32) DEFAULT NULL COMMENT '管理员uid',
`is_original` varchar(1) DEFAULT '1' COMMENT '是否原创(0:不是 1:是)',
`author` varchar(255) DEFAULT NULL COMMENT '作者',
`articles_part` varchar(255) DEFAULT NULL COMMENT '文章出处',
`blog_sort_uid` varchar(32) DEFAULT NULL COMMENT '博客分类UID',
`level` tinyint(1) DEFAULT '0' COMMENT '推荐等级(0:正常)',
`is_publish` varchar(1) DEFAULT '1' COMMENT '是否发布:0:否,1:是',
`sort` int(11) NOT NULL DEFAULT '0' COMMENT '排序字段',
`open_comment` tinyint(1) NOT NULL DEFAULT '1' COMMENT '是否开启评论(0:否 1:是)',
`type` tinyint(1) NOT NULL DEFAULT '0' COMMENT '类型【0 博客, 1:推广】',
`outside_link` varchar(1024) DEFAULT NULL COMMENT '外链【如果是推广,那么将跳转到外链】',
`oid` int(11) NOT NULL AUTO_INCREMENT COMMENT '唯一oid',
`user_uid` varchar(32) DEFAULT NULL COMMENT '投稿用户UID',
`article_source` tinyint(1) NOT NULL DEFAULT '0' COMMENT '文章来源【0 后台添加,1 用户投稿】',
PRIMARY KEY (`uid`, `oid`),
KEY `oid` (`oid`)
) ENGINE = InnoDB
AUTO_INCREMENT = 59
DEFAULT CHARSET = utf8 COMMENT ='博客表';存在的疑问
- 抽出的代码如搜索结果的显示部分,人工阅读可以知道点击不同位置时触发的action应该作为模板的空,而显示更多对应的action应该作为搜索显示的一部分
- 代码好像越往后拓展雪球滚得越大,按照个人理解,
${base_url}/#/list页面承担了所有查找功能而不仅仅只有关键字搜索功能,这导致事件处理部分判断条件繁多,调用API数量也很多,是否背离了简单的搜索这个功能需求



